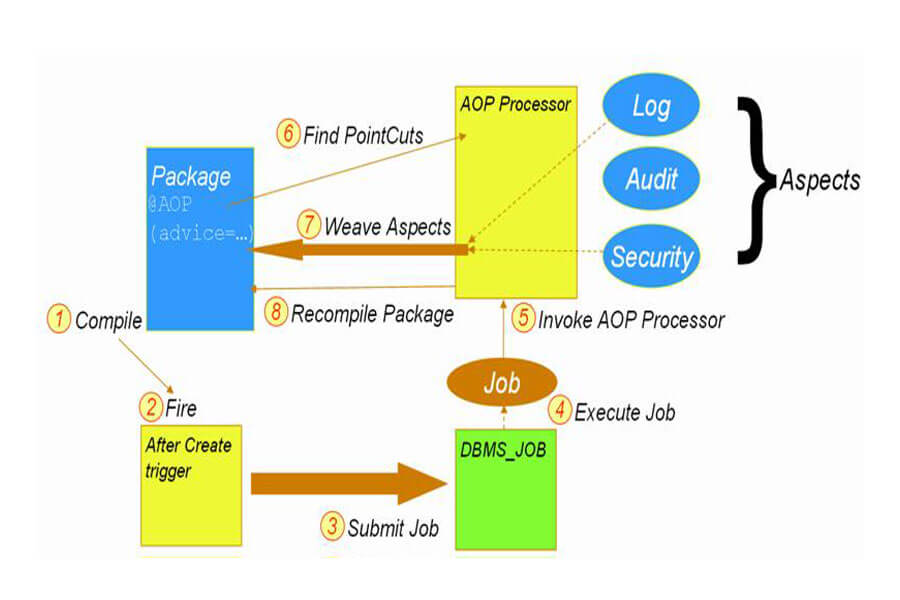
Chuyển tải yêu cầu của người dùng vào hệ thống phần mềm chưa bao giờ là công việc đơn giản. Dù có nhiều phương pháp giải quyết như: lập trình hướng đối tượng (OOP), hướng thành phần… Tuy nhiên, chỉ giải quyết một số khía cạnh. Chưa có phương pháp nào giải quyết yêu cầu đan xen ở mức hệ thống hay còn gọi là (cross – cutting concern). Để giải quyết vấn đề này mô hình lập trình hướng khía cạnh AOP đã ra đời. Cùng Dotnetguru tìm hiểu mô hình này ngay sau đây.
AOP là gì?
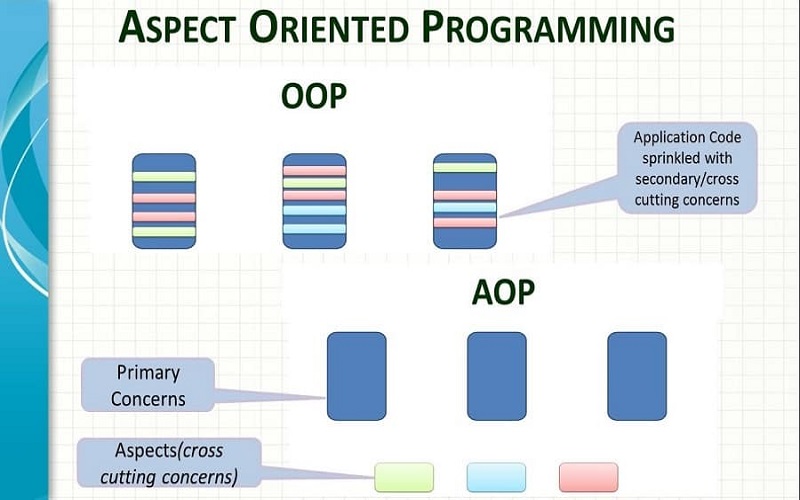
Lập trình hướng khía cạnh – Aspect Oriented Programming AOP. Đây là một kỹ thuật trong lập trình (gần giống như lập trình hướng đối tượng OOP). Nhằm phân tách chương trình thành các module riêng rẽ, phân biệt và không phụ thuộc nhau.
Khi hoạt động, chương trình sẽ kết hợp các module với nhau. Nhằm để thực hiện các chức năng nhưng khi sửa đổi 1 chức năng thì chỉ cần sửa 1 module. AOP không phải dùng để thay thế OOP mà AOP phát triển dựa trên OOP bổ sung cho OOP.
Aspect Oriented Programming AOP ra đời nhằm sử dụng hiệu quả Object Oreted Programming OOP. Tăng cường tối đa khả năng tái sử dụng của mã nguồn.
Nếu như OOP hữu hiệu trong việc lập mô hình hành vi chung của các đối tượng tuy nhiên nó không giải quyết thỏa đáng những hành vi liên quan đến đối tượng, thì AOP giải quyết được vấn đề này và rất có thể sẽ có bước phát triển lớn kế tiếp trong phương pháp lập trình.
Ưu điểm của lập trình hướng khía cạnh AOP
Một vài nét về ưu điểm và nhược điểm của Aspect Oriented Programming AOP. Đó là:
Ưu điểm AOP
- Ưu điểm đầu tiên của lập trình hướng khía cạnh AOP là thiết kế đơn giản: “You aren’t gonna need it (YAGNI)”, Người dùng chỉ cài đặt những thứ mà họ thực sự cần mà không bao giờ cài đặt trước.
- Ưu điểm thứ hai của Aspect Oriented Programming là cài đặt chương trình một cách trong sáng: mỗi một module chỉ làm cái mà nó cần phải làm, giải quyết được hai vấn đề code tangling và code scattering
- Ưu điểm thứ ba chính là tái sử dụng dễ dàng.
Những yêu cầu mà người Aspect Oriented Programming AOP cần có đó là có kỹ năng cao: độ trừu tượng của chương trình cao, và phải xử lý luồng chương trình phức tạp.
Nhược điểm AOP
- Khái niệm khá trừu tượng cùng độ trừu tượng của chương trình cao.
- Luồng chương trình tương đối phức tạp.
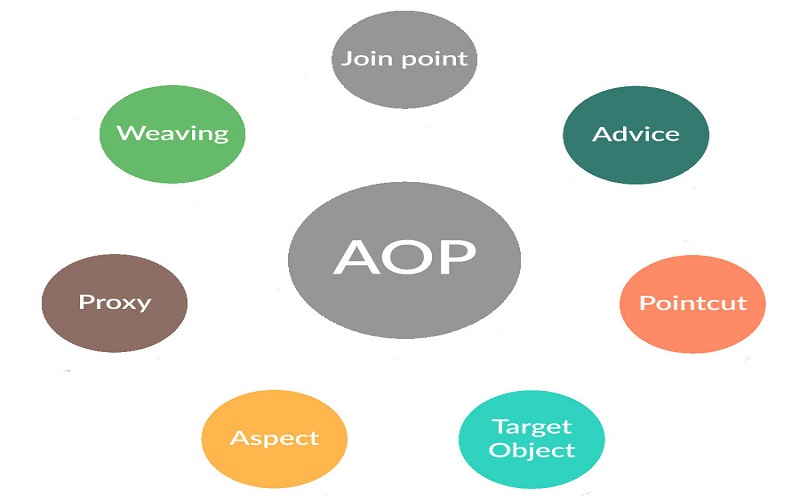
Các thuật ngữ mới trong lập trình hướng khía cạnh AOP
- Thuật ngữ Core concerns: hàm chính của chương trình (những method phải thực hiện log)
- Thuật ngữ Crossutting concerns: những chức năng khác của chương trình, ví dụ như security, logging, tracing, monitoring..
- Thuật ngữ Join points: một điểm của chương trình. Đây là nơi bạn có thể chèn những custom action của mình.
- Thuật ngữ Pointcut: có nhiều phương pháp giúp xác định joinpoint, những cách như vậy được gọi là pointcut.
- Thuật ngữ Advice: những xử lý phụ được bổ sung vào xử lý chính, code nhằm thực hiện các xử lý đó sẽ được gọi là Adivce.
>>> Xem thêm: MVC là gì? Tổng quan mô hình MVC trong lập trình
Các ngôn ngữ và framework hỗ trợ AOP
Có một số ngôn ngữ lập trình và khung công tác được phát triển với mục đích hỗ trợ AOP, bao gồm: (AspectJ – Java), (AspectC++ – C++) và (PostSharp – .NET).
Hơn nữa, các ngôn ngữ lập trình phổ biến như Python, JavaScript và Ruby cũng có thư viện và framework cung cấp khả năng AOP. Chẳng hạn như là Aspect.py, Aquarium, Aspect-R & Aspect.js.
Vai trò của AOP trong bối cảnh nền tảng AppMaster
Trong bối cảnh của nền tảng AppMaster, Aspect Oriented Programming (AOP) có thể được áp dụng hiệu quả. Nhằm để quản lý những mối quan tâm xuyên suốt trong nhiều loại ứng dụng web và mobile.

Ví dụ: nhà phát triển tạo các khía cạnh để xử lý tác vụ như điền nhật ký, giám sát hiệu suất & bộ nhớ đệm,.. Tạo ra một cơ sở mã mô-đun đồng thời dễ bảo trì hơn. Việc áp dụng nguyên tắc Aspect Oriented Programming (AOP) giúp tăng tốc phát triển, giảm gánh nặng bảo trì. Phù hợp với mục tiêu của nền tảng đó là đẩy nhanh quá trình xây dựng, phát triển ứng dụng cũng như quản lý nợ kỹ thuật tốt hơn.
Hơn nữa, lập trình hướng khía cạnh AOP cho phép khách hàng AppMaster giải quyết những yêu cầu cấp doanh nghiệp và phức tạp. Bằng cách cung cấp cách tách biệt rõ ràng những mối quan tâm xuyên suốt khỏi logic kinh doanh trong ứng dụng của họ.
>>> Xem thêm: Lập trình viên Android cần học những gì? Mức lương Android Developer ra sao?
Phát triển ứng dụng dựa trên AOP
Hiện nay, AOP được sử dụng nhiều trong việc phát triển ứng dụng. Hay phát triển hệ thống bằng phương thức khác. Việc phát triển hệ thống dựa trên AOP gồm các công đoạn: nhận định, cài đặt và kết hợp các concern để xây dựng. Các bước thực hiện như sau:
- Aspectual decomposition – Phân tích bài toán theo khía cạnh: cần xem xét yêu cầu, từ đó tìm ra chức năng chính. Đồng thời tim ra chức năng nào cắt ngang hệ thống. Khi đã xác định được cần phải tách chức năng cắt ngang này ra khỏi chức năng chính.
- Concern Implementation – Xây dựng chức năng: Tại bước này, các chức năng sẽ được cài đặt độc lập với nhau.
- Aspectual Recomposition – Kết hợp các khía cạnh để tạo hệ thống hoàn chỉnh: bằng cách tạo các Aspect để chỉ ra quy luật kết hợp. Đây được gọi là quá trình dệt mã, sử dụng thông tin có trong Aspect để tạo ra hệ thống cuối cùng.
Thực tế, người ta nghiên cứu, áp dụng phát triển ứng dụng AOP vào rất nhiều ngôn ngữ lập trình như: C, C#, PHP, Java,… Một số dự án nghiên cứu AOP quan trọng có thể kể đến là: AspectJ, Aspect#, AspectC++, Aspect Werkz, Spring AOP, Jboss AOP, JAC.
Một vài chia sẻ từ Dotnetguru về lập trình hướng khía cạnh AOP. Chắc có lẽ bạn đã hiểu được AOP là gì rồi đúng không? Hy vọng những thông tin trong bài viết trên có thể giúp các bạn có cái nhìn tổng quát về Aspect Oriented Programming (AOP).